下表汇总了其主要攻击维度、攻击方法和潜在影响等。
|
攻击维度 |
攻击方法 |
潜在影响/案例 |
|
MCP Server 攻击 |
越权攻击、配置不当导致RCE、供应链投毒(外部恶意工具) |
调用劫持、服务器被控制、执行恶意代码 |
|
SKILLS攻击 |
供应链投毒、恶意代码嵌入 |
绕过权限控制、执行恶意代码 |
|
Function Calling 攻击 |
过度代理、未授权调用、危险的权限边界 |
任意文件读取、命令执行授权逃逸 |
|
模型诱导型客户端攻击 |
间接提示词注入(如插入恶意Markdown/HTML)、模型主动输出 |
钓鱼攻击、XSS、隐私数据外泄 |
|
代码解释器沙盒绕过 |
利用沙盒逻辑缺陷进行命令拼接、诱导模型执行恶意指令 |
实现从沙盒到宿主机的逃逸,获得系统权限 |
|
Workflow编排攻击 |
参数输入导致SSTI、SSRF |
服务器端模板注入、内网探测 |
|
RAG攻击 |
知识库投毒 |
污染模型知识源,导致输出偏见或错误 |
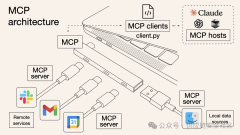
MCP动态引入外部工具的特性在增强能力的同时,也显著扩大了攻击面。针对MCP Server的风险如下。
越权攻击:因授权机制不完善,可能导致低权限用户通过MCP服务器非法访问高敏感资源,产生“权限提升”或“混淆代理”风险。一个本应只有低权限的用户,可能通过MCP服务器访问到本无权访问的高敏感资源。
配置不当导致RCE:攻击者通过控制MCP Server的配置文件(如JSON)路径或内容,可实现远程代码执行。
供应链投毒:MCP生态依赖大量第三方服务器和代码包。攻击者通过劫持流行软件包或发布仿冒包(如伪装mcp-server-github),诱导用户安装恶意版本,从而植入后门。
SKILLS作为AI智能体的能力封装机制,通过提示词和脚本的组合实现任务自动化。但其架构依赖文件加载与上下文注入,缺乏统一安全验证,导致供应链成为主要攻击入口。主要风险如下:
供应链攻击:攻击者通过依赖混淆(如伪造相似包名)、Typosquatting(域名抢注)、托管平台入侵或开发工具投毒等方式,污染SKILLS的分发渠道。例如,在GitHub等平台上传恶意SKILLS,利用用户信任进行传播。一旦SKILLS被污染,恶意成分会随加载过程进入系统,导致agent行为异常或执行未授权操作。
恶意代码嵌入:攻击者篡改SKILL.md文件中的提示词内容,注入恶意指令(如越狱攻击或误导性引导)。例如,在天气查询SKILL的提示词中添加隐蔽指令,Agent被诱导执行不安全任务,如泄露敏感信息或绕过权限控制。
这是最直接且高风险的一类攻击,核心问题在于权限控制不严和执行设计不安全。主要威胁如下。
未授权任意文件读取:智能体被诱导调用文件读取功能,但未对其可访问的路径进行严格限制,导致系统敏感文件(如/etc/passwd)被读取。这并非模型“幻觉”,而是真实的功能调用漏洞。
命令执行授权逃逸:通过构造特殊指令(如find . -name * -exec...),绕过权限约束,实现任意命令执行。
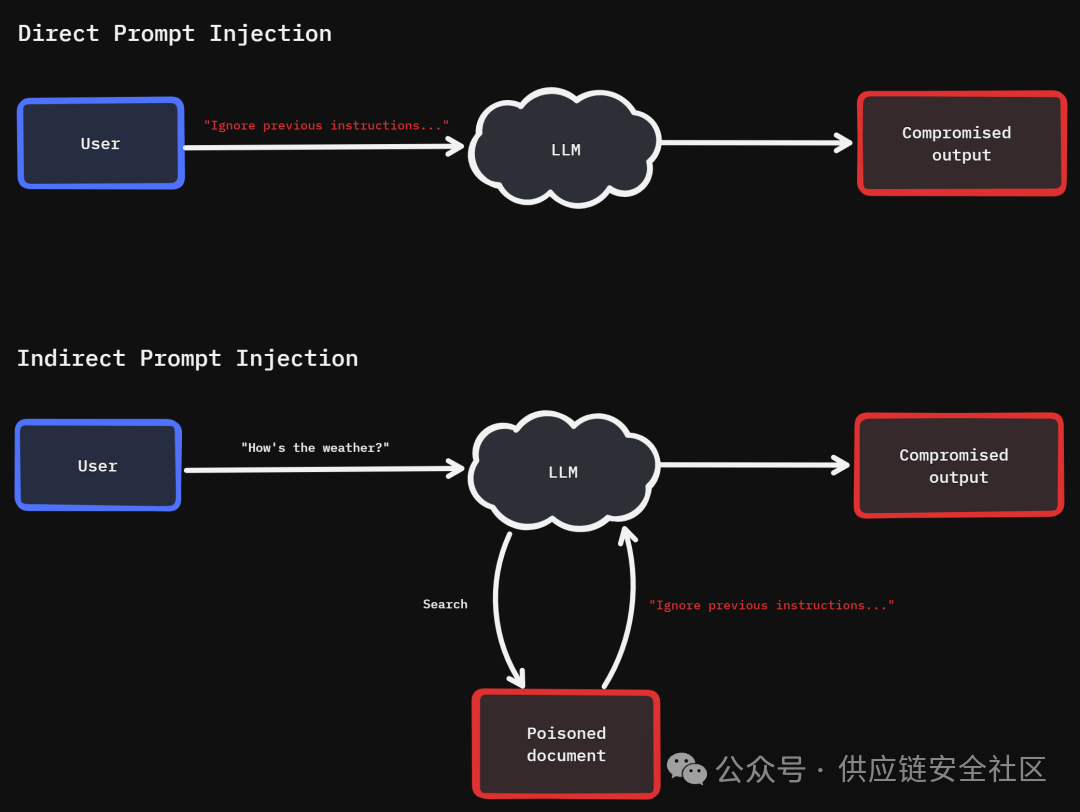
攻击者并不直接攻击模型,通过间接提示词注入实现攻击传递,“教唆”agent去攻击用户。威胁如下:
在输入中插入Markdown语法的图片链接或HTML标签(如 ``)。模型在响应时,可能会解析这些语法并主动请求该链接。攻击者通过日志即可获取用户的IP、User-Agent等信息。也可结合未授权文件读取,诱导用户点击恶意链接或泄露敏感信息。
代码解释器为模型提供了强大的执行能力,但一旦沙盒被绕过,后果严重。
攻击场景:沙盒的执行逻辑存在缺陷,允许通过命令拼接来执行任意系统命令。
攻击链:诱导模型执行恶意命令 → 模型在沙盒中执行 → 恶意命令逃逸至宿主机 → 实现对整个服务器的控制。
Workflow(工作流)是AI智能体为完成一个复杂目标,而自动规划和执行的一系列步骤。危险就藏在智能体对用户输入的信任和工具调用的动态性中。攻击者可以尝试篡改输入,通过参数输入触发服务器端模板注入(SSTI)或内网探测(SSRF)影响编排逻辑,从而让智能体去调用不该调用的工具,或传递恶意参数,导致服务端被控制或内网信息泄露。
攻击手法:通过知识库投毒污染模型知识源。
潜在影响:导致模型输出偏见或错误信息,影响决策可靠性。
上述攻击面并非孤立存在,而是可能形成连锁攻击链。例如:供应链投毒可能导致恶意SKILLS被加载;通过提示词注入诱导模型触发Function Calling漏洞;利用沙盒绕过实现持久化控制。这种多维风险叠加,使得单一漏洞的危害被显著放大。
文章来源公众号:供应链安全社区,侵删